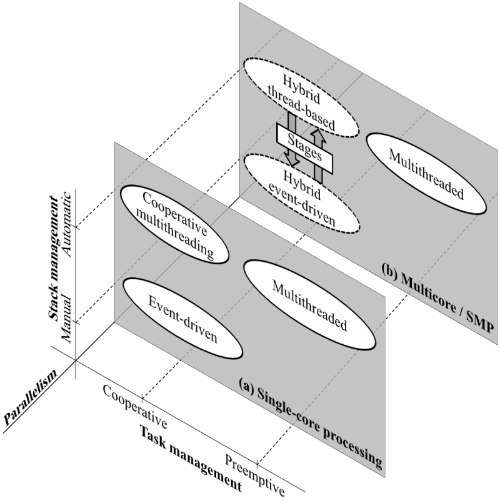
Figure 1: Three axis concurrency graph.
| Tiago Salmito, Ana Lúcia de Moura & Noemi Rodriguez |
| 1Departmento de Informática |
| Pontifícia Universidade Católica do Rio de Janeiro (PUC-Rio) |
| Rua Marquês de São Vicente, 225 - CEP 22.451-900 - Rio de Janeiro - RJ - Brazil |
| {tsalmito | amoura | noemi}@inf.puc-rio.br |
Abstract
Over the last years a number of works have proposed hybrid concurrency models, combining threads and events, typically with a bias towards one of the paradigms. It is important to have a clear understanding of this combination and of its impact on concurrent and distributed programming. This work presents a classification of hybrid concurrent systems and describes a collection of representative systems within a common framework.
Keywords: Hybrid concurrency, Thread, Events, Concurrent programming
A concurrent system must, by definition, handle concurrent tasks. This can be done in a number of ways, the most popular of which are, to this day, threads and events. In some cases, there is an intuitive mapping of the tasks to be handled to the abstraction that will support them. It is natural, for instance, to design a web server using a separate thread for each incoming client request. Although several experiments have shown that event-based servers can achieve better results when requirements such as scalability and performance are taken into consideration [19, 18], the thread-based programming style is still widely considered the most adequate for this specific class of applications [24]. On the other hand, events are a suitable abstraction for modelling, for instance, loosely-coupled interactions in peer-to-peer distributed systems. Threads can be important in this setting to harness the processing power available in multicore systems, but they are not the natural programming style.
Although both abstractions — preemptive multithreading and events — have had their share of criticisms [17, 14, 24], most concurrent systems today still force the programmer to choose one of these approaches and to deal will all the resulting disadvantages. Over the last years, however, systems that combine the two concurrency models have been gaining attention.
This combination can occur in a variety of forms. For instance, to protect event-based programs from blocking themselves on synchronous invocations, several systems run independent event loops in separate threads or launch new threads when faced with blocking operations [18]. Another class of solutions seeks to minimize the effects of what Adya and others [1] have called stack-ripping — the fact that no local stack information is kept beween the execution of different event handlers — by implicitly creating closures that encapsulate state, making it available to the continuation of their corresponding computations [21, 9]. In all of these cases, only one concurrency model is presented to the programmer, and the other is used as an implementation aid. Some authors have proposed more sophisticated architectures that intend to bridge the gap between the most adequate programming style and the implementation advantages of the alternative model. These architectures strive to enable programmers to design parts of the application using threads, where threads are the appropriate abstraction (such as per-client code in server applications), and parts using events, where they are more suitable (e.g. for asynchronous I/O interfaces) [14].
Although there is a reasonable amount of work addressing the combination of multithreading and events, there seems to be little discussion about the relationship among the different proposals and the application scenarios in which each one of them would be suitable. We are specifically interested in the role these models have in distributed systems. Current execution requirements often include elasticity and scalability, demanding the use of distributed resources, commonly available in clusters and in the increasingly popular cloud infrastructures. Therefore, we believe an important issue when analysing a concurrency model is whether it can be used in applications executing in these shared-nothing environments.
In this paper, we try to achieve a better understanding of concurrency models that combine threads and events, also called hybrid systems [14, 8]. We propose a classification of hybrid systems and discuss some proposals that fall into each of the identified hybrid concurrency classes, showing how they benefit from the combination of two concurrent models.
Ousterhout [17] and von Behren [24] are among the most cited contenders on the two sides of the events×threads debate. It is interesting to view the combination of paradigms in light of their arguments. Ousterhout claims that events are easier to get started with: because there is no concurrency among handlers, there is no need to worry about synchronization or deadlock. Besides, he states that events are typically faster than threads on single CPUs, considering that there is no context switching or synchronization overhead. von Behren [24] argues that many of these advantages are due to the cooperative multitasking model on which events are based, which can also be used as a basis for user-level threads. Another recurring issue in the debate is that about control flow. von Behren claims that event-based programming tends to obfuscate the control flow of applications: the frequent call-return pattern requires the programmer to manually maintain state in event-based programming, while threads model this pattern naturally. It seems that the discussion about the best model is intrinsically linked to the type of application at hand: von Behren focuses his discussion on high-concurrency servers. On the other hand, there are applications for which the call-return pattern is not the most appropriate: if, for instance, a client needs to trigger a reaction after having received a minimum number of responses, a state machine may in fact be the best alternative.
Despite his criticisms, Ousterhout explicitly states that threads should not be abandoned, and points out that they are necessary when true CPU concurrency is needed, indicating that it may be advantageous to combine threads and events in a single application. In fact, the emergence of multicore architectures, as well as the need to execute applications over shared-nothing architectures to provide for elastic resource usage, has led several authors to propose hybrid concurrency models, combining threads and events, over the last decade [4, 5, 9, 10, 14, 22, 25, 26].
Figure 1 extends the graph used by Adya [1] – originally to discuss the orthogonal natures of stack and task management – with an additional axis that introduces parallelism as provided by multi-CPU architectures. In plane (a), the “multithreaded” region describes preemptive multithreading with automatic stack management, as offered by operating system threads. In the “event-driven programming” region, handlers yield control to the event scheduler, requiring manual effort for maintaining state information between invocations. Adya argues that it is possible to use cooperative task management while preserving the automatic stack management that, according to him, make the programming language “structured”. However, the proposed merged solution contemplates only single-CPU environments. In this work, we introduce a third axis in the graph, in order to make it clear that we need to exploit multi-CPU parallelism.
In plane (b) of Figure 1, the three original regions are projected into their counterparts in a multi-CPU environment. The “multithreaded” region maintains the same characteristics as before, except for the fact that now threads may be executed with real parallelism. The two regions on the left are the ones that will interest us. Both represent hybrid systems combining features of threads and events, but with different bias towards one of the two abstractions. We will use this bias as a basis for identifying, understanding and analyzing different classes of hybrid models. An event-driven hybrid model results from extending the classical, single-threaded, event-driven model to multi-CPU environments by running multiple event loops in parallel. In constrast, a thread-based hybrid model maintains the combination of cooperative multitasking and sequential control flow proposed by Adya, providing the programmer with thread-like abstractions.
The third model of hybrid systems that we have identified – the staged model – does not have a clear bias towards either threads or events, and exposes both abstractions to the programmer. Systems based on this model are typically decomposed into self-contained modules that communicate through event queues. Internally, modules use threads to handle events concurrently. This class of systems is largely inspired by the SEDA architecture [25], in which modules are called stages. In plane (b) of Figure 1, we represent this alternative as a rectangle lying between hybrid thread-based and hybrid event-based systems.
In the next sections, we discuss each of the identitifed hybrid concurrency models in more detail, providing some examples of systems that fall into each category.
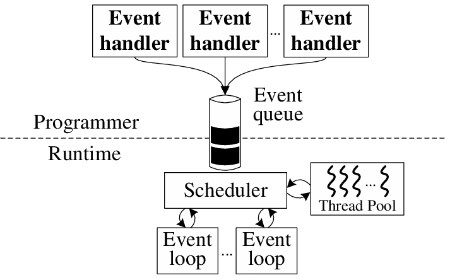
The event-driven hybrid concurrency model emphasizes the advantages of programming with events, mainly related to cooperative, user-level, multitasking, while eliminating the limitation of working with a single CPU. In order to support parallelism and benefit from current multicore architectures, the event-driven hybrid model uses two or more concurrent event-loops, typically one per CPU. Figure 2 depicts a conceptual representation of the event-driven hybrid concurrency model.
The introduction of parallelism among handlers brings the problem of synchronization back to light. If multiple event-handlers execute simultaneously with access to a global memory, the programmer will have to deal with the classic data-race problems. Event-driven hybrid models typically try to avoid this scenario, controlling access to global memory in different ways.
Conceptually, parallel event handlers could even be executed in different OS processes, thus eliminating the problem of shared memory and introducing the possibility of executing in shared-nothing environments. However, all the proposals that we identified in this class describe sets of handlers executing inside the same address space, thus eliminating the possibility of distribution.
As regards user-level scheduling, most event-driven hybrid models resort to thread pools to execute the application-level event-handlers with operating system threads. This is interesting in that it allows the application to control the real parallelism involved, by configuring the number of OS threads that will be spawned. This scheduling layer also implies in greater portability than the direct use of OS threads.
We next present two proposals of event-driven hybrid concurrency: the libasync-smp library [5] and the inContext [26] library.
libasync-smp. Libasync-smp [5] is an extension of the libasync [15] library – an event-based library for C/C++ applications – that provides parallelism by simultaneously executing different callbacks on multiple CPUs.
A libasync-smp program is typically a process with one OS thread per available CPU. Each of these threads repeatedly executes callbacks (event handlers) it obtains from a ready queue. All threads share the global process state: global variables, file descriptors, etc. To coordinate this access, the library introduces the notion of coloring. Each callback is associated to a color (a 32-bit value), which is analogous to a mutex. Callbacks with the same color cannot be executed in parallel. By default, all callbacks are mutually exclusive i.e., they have the same color. This stimulates the programmer to introduce callback parallelism in an incremental manner.
Libasync-smp does not support distributed execution. The entire application runs in a single operating system process with a single shared queue of pending events.
InContext. InContext [26] is an extension to the the MACE [13] event-driven system. In MACE, event-handlers are atomic and are run in a single thread.
An InContext application is again executed by a pool of threads which are assigned to pending event-handlers whenever they become idle. Event-handlers can access global data, and to control race conditions, the model introduces the notion of context. InContext defines three types of contexts: none, anon, and global. An event-handler may transition between different contexts during execution, but its actions are restricted by the current context. When running in context none, the event-handler may not access any global data. In context anon, event-handlers have read-only access to global data, and finally, in context global, an event handler may read or write global data. anon and global contexts are comparable to read and write locks, but with only one instance of readers and writers: the implementation guarantees that only one event runs in global context at a time and that an event handler does no enter the anon or global context before all earlier event handlers executing in global context have committed. The programmer must annotate the handler manually with the transitions between contexts, and it is up to the programmer to guarantee that accesses to global variables are executed in the appropriate context..
The event-based hybrid concurrency model is simple to understand and to implement, and provides the flexibility of scheduling traditionally associated with events. However, multi-CPU execution brings data races back if event-handlers have access to a global memory. The two solutions we have described provide the programmer with simplified versions of conventional locks to deal with this issue. The colors used by libasync-smp correspond closely to mutual exclusion locks. By default, all handlers execute under one single lock: when the programmer introduces different colors, he is in fact introducing different mutexes. InContext, on the other hand, provides the programmer with a read-write lock: none event handlers are the ones that need no lock, anon handlers are “readers” and global handlers are “writers”. The simplification in this case is that a single instance of the read/write lock is provided automatically by the system.
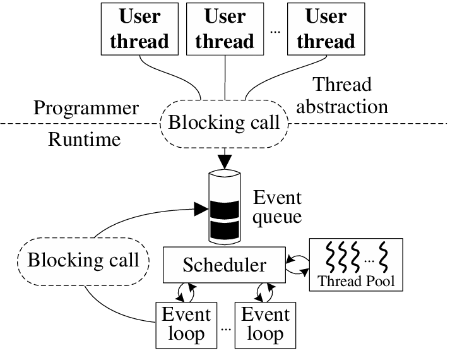
As discussed in the introduction of Section 2, this alternative corresponds to the extension of cooperative multithreading to multi-CPU environments. Proposals for thread-based hybrid concurrency support the idea that control flow is better expressed through threads, and that the main problems with threads can be “fixed” by a user-level implementation based on events [4]. Figure 3 shows a graphical representation of the components of such models.
As in the single CPU case [1], blocking system calls are translated into asynchronous calls (events) through the use of wrappers. Control flow is cooperatively passed to the scheduler and the state of the user-level thread is maintained while its execution is suspended. Upon the completion of the requested operation, the scheduler restores the state of the thread and resumes its execution, hiding from the programmer the inversion of control that is typical of events. To make inversion of control transparent, these systems can resort to continuations [14] or to coroutines and closures [4, 21].
The effective use of multiple CPUs is again attained with a pool of OS threads. The user-level scheduler may run an arbitrary number of concurrent event loops, which are constantly consuming events from the event queue. In some cases, specific event loops are assigned for dealing with specific operations (such as blocking system calls or dealing with network operations), and have exclusive event queues.
User-level implementations allow for flexible scheduling and avoid the overhead of OS context switches, but, again, when executed in multiple OS threads, can be subject to data races and cache issues. Each of the systems in this class deals with this issue in a specific way.
We next present three implementations that employ thread-based hybrid concurrency: the Capriccio thread package [4], which uses coroutines to transform a seemingly threaded program into a cooperatively-scheduled event-driven program with the same behavior; the Scala actors library [9], which is inspired by the actor paradigm; and the proposal of Li and Zdancewic [14], which uses Haskell monads to offer a thread abstraction implemented by an event-driven execution engine.
Capriccio Capriccio [4] is a C library and that provides a POSIX threads [12] compatible API using user-level cooperative threads. Cooperative multitasking is implemented with coroutines [6]. Capriccio provides wrappers to I/O blocking functions that call asynchronous I/O counterparts and yield control back to the scheduler.
One interesting feature of Capriccio is the way it explores the flexibility of user-level scheduling. The system acquires information about resource usage and blocking frequency of each user-level thread along execution. The scheduler can use this information to implement different policies, such as giving priority to threads that are nearer completion or to threads that will shortly release resources.
Capriccio’s implementation is for a single-CPU architecture, and thus benefits from the atomicity derived from cooperative multithreading in this environment. This and the library’s scheduling model preclude Cappricio’s usage in distributed environments.
Scala Actors. The actor model [2] describes a distributed application as a set of objects that interact through asynchronous messages. The Scala actors library [9] provides support for receiving messages in two alternative ways. The first one is a thread-style receive, which will block the current thread until the expected message is available. The second form is the non-blocking react, which encapsulates the code to be executed upon message arrival in a continuation of the current computation. This continuation, which is resumed only when the expected message becomes available, represents the suspended actor.
Once again, support for multi-CPU concurrency is provided by a pool of worker threads (defined by the underlying Java virtual machine) which repeatedly fetch work to execute from a queue of tasks. Tasks are generated either by spawning a new actor or by a matching send/react pair. In the latter case, the new task is a closure containing the continuation of the receiving actor. A worker thread is released either when its associated actor terminates or when it executes react. To deal with the chance that all worker threads become blocked, the library implements a simple scheduling policy: if there is at least one task in the queue and all worker threads are blocked, a new worker thread is created.
Because Scala actors are implemented as Java objects, the restriction that they communicate only through message passing is left to programmer discipline [16]. Object references passed in messages can easily be shared among actors and thus will be subject to conventional data sharing issues.
The actor concurrency model is a convenient model for use in distributed memory settings, although the authors have not explored the Scala actor library in distributed architectures.
Monadic hybrid concurrency. Li and Zdancewic [14] explore features of the Haskell programming language to implement a cooperative multitasking library which has much in common with Capriccio. In their proposal, application code is written sequentially on a user-level thread abstraction. using the Haskell ’do’ syntax.
Each user-level thread is represented internally as a sequence of steps punctuated by system calls which are the potentially blocking points. The queue of ready tasks contains continuations of user-level threads. A pool of operating system threads repeatedly takes one of these continations and executes it up to the next system call. Depending on its nature, this system call may be dispatched to a separate event loop. When the system call results are available, the updated continuation of the task is put in the ready task queue. Haskell’s lazy evaluation is important for controlling the execution of the sequential execution steps.
This approach is very similar to the Capriccio user-thread mechanism, with the difference that it hides control inversion using continuations instead of coroutines. To represent continuations, Li and Zdancewic use CPS monads.
The system assumes that all steps are thread-safe and can be performed in parallel. This is made easier by programming in a functional language, Timing dependent I/O, or any other thread-unsafe operations, can be handled either by using separate, sequential, event loops, or by explicit synchronization primitives.
Distributed-memory environments are not considered, and it is not intuitive how this proposal could be extended to address them.
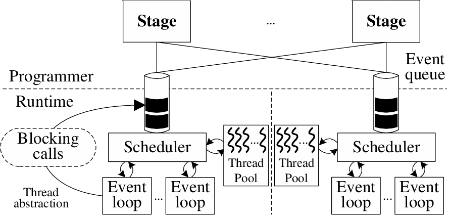
The staged concurrency model introduces a modular approach for the design of concurrent systems combining events and threads. In this approach, the processing of tasks is divided into a series of self-contained modules (stages) connected by event queues.
Each stage has its own event handler – which implements the stage’s functionality – and a thread pool. The threads in the pool remove events from the stage’s input queue and execute parallel instances of the event handler. Typically, the processing of an event generates one or more events that are dispatched to other stages, until the processing of the corresponding task is completed. Figure 4 illustrates the basic components of the staged concurrency model.
Systems using the staged approach typically explore its modularity to tune task scheduling and resource sharing. Scheduling policies are local to each stage, thus allowing systems to control the level of concurrency at a finer grain and to employ appropriate scheduling policies for the specific characteristics of each stage. Stages can also be convenient barriers for controlling access to memory or other resources.
The concept of stages was introduced by the work on SEDA (Staged Event-Driven Architecture) [25]. Although the original architecture is designed for a single host, the staged model can be quite naturally extended to distributed memory environments.
We next discuss three approaches in the staged concurrency class: the SEDA architecture itself; MEDA [10], focused on master-worker applications, and the Aspen programming language [22].
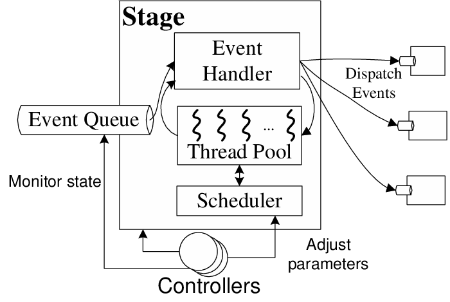
SEDA. The Staged Event-Driven Architecture (SEDA) was designed for implementing highly-concurrent servers. In SEDA, a user’s request is wrapped as an event, and is processed by series of stages connected through event queues.
A SEDA stage, pictured in Figure 5, is composed by an event queue, a thread pool, a controller, and an event handler. Each stage acts as an independent multithreaded event-driven entity. Stages may block internally (for example, by invoking a library routine or blocking I/O call), and use multiple threads for concurrency. The controller is responsible for scheduling event handling and adjusting the stage concurrency level. In order to do this, it monitors information such as input queue length, response time, and throughput.
The support for modularity and adaptive concurrency control makes SEDA a widely studied approach [8, 11, 22].
In the original SEDA design, all stages were executed inside a single OS process, leaving memory isolation to programmer discipline. Besides, connections between different stages are achieved by a shared memory queue, making the design unsuitable for distributed memory environments.
MEDA. MEDA [10] is a staged architecture based on SEDA, specifically designed to address the master-worker paradigm, commonly used in parallel programming.
MEDA takes advantage of the fact that master-worker applications are naturally structured in stages. The master typically executes initialization, work distribution, and result collection/combination steps. Workers typically process work units and return results to the master. In the MEDA architexture, there are pre-defined stages corresponding to these steps. Worker stages are replicated throughout the network.
MEDA’s goal from the beginning was to extend SEDA’s single host model to distributed memory environments. SEDA event queues are implemented in MEDA as network queues, providing each stage with handlers for remote queues which can be implemented in a different OS process or in a different host. MEDA makes no provision for concurrency control inside each stage.
The authors explore the flexibility of user-level scheduling to increase throughput and responsiveness by introducing priorities in the handling of event queues.
Aspen. An Aspen [22] program is structured as a collection of modules. Similarly to the approach taken by SEDA, modules communicate through queues of events, bringing the concept of stages to the programming language level. Each Aspen module has an input event queue and one or more output queues. Connections between modules, associating output queues to specific stages, are defined in the application code, in a separate configuration file.
Aspen is intended for coding network services, including connection-oriented servers. This type of application is specifically supported by introducing the concept of flow, which captures the idea of work elements that must be processed in sequential order. Aspen assigns all work elements in the same flow to a single worker thread, ensuring sequentiality.
Each Aspen module has its separate addressing space: variables and file descriptors are private to each module. This avoids data sharing issues and allows the Aspen model to be implemented in distributed memory environments.
Internally to each module, Aspen makes some provisions for avoiding race conditions. In the first place, the programmer can specify per-flow variables. Aspen automatically creates a copy of such variables for each flow. This facilitates maintaining state between work elements in a single flow, allowing the use of a module’s global memory in a protected way. Secondly, the Aspen model does not allow parallel execution of flows that access shared resources (either memory or files).
When writing a concurrent system, the model to be chosen depends heavily on the granularity of the tasks to be executed in parallel. This granularity, as well as the performance and scalability requirements, will define the best choice.
To discuss the relationship between granularity and concurrency model, we will once again turn to Figure 1. In plane (a), the “event-driven” region was appropriate, in single CPU systems, for handling fine-grained concurrency, as found in GUIs. Just as events are good for describing user-interface handlers, which are typically short chunks of code, hybrid event-driven systems remain a convenient way of coding short handlers in multi-CPU environments, in plane (b).
For coarser-grained applications, threads are seen as the best abstraction for the programmer. To benefit from the advantages of cooperative task management, in plane (a) the “cooperative multithreading" region is the sweet spot indicated by [1]. In plane (b), the corresponding region is the hybrid thread-based model. In this model, control flows are transparently broken up in chunks typically delimited by blocking system calls.
The staged model maintains this same idea of decomposing control flow in a series of steps, with the difference that these tasks have a larger granularity and that the task of breaking up the application is assigned to the programmer, because it depends on the structure he envisions for the application.
Both the thread-based and the staged hybrid models can be appropriate to describe large control flows. The difference between them arises when analysing issues of resource sharing, distribution, and performance.
As regards solutions for controlling resource sharing and supporting distributed memory environments, staged models naturally pave the way. It is natural to associate each stage to a separate addressing space, thus allowing stages to be executed in different hosts and reducing the problem of data sharing to the internal context of each stage. However, in some cases it is necessary for different steps to share information, when steps are tightly coupled. In this case, it may be more convenient to use a thread-based system, or even, in a staged-based model, combine tightly coupled steps in a single stage.
Existing staged systems have not, in general, payed much attention to the issue of internal concurrency. The exception is the Aspen model, which enforces protection of global data, although the initial prototype of the system does not include this enforcement. One idea would be to apply one of the approaches described for event-based hybrid systems, such as the event coloring of libasync-smp, or the event execution contexts of InContext. Another idea would be to avoid memory sharing among worker threads, using message-passing also for communication among event-handlers inside a stage [23, 3].
As regards performance, the choice of a model will depend heavily on the metrics of interest. Event queues can result in unbounded latencies, which are unaceptable in most application scenarios that have real-time requirements. The main problem with the use of staged concurrency in scenarios that need low latency is the cost of enqueing dequeuing units of work at each stage [8]. In such scenarios, thread-based hybrid models can be useful. On the other hand, staged concurrency maintains high throughput when low latency is not a major requirement, such as on image processing applications [8] or video-on-demand streaming servers [22].
Systems based on the staged model can also offer performance gains due to the possibility of fine tuning. Each stage can handle events with a different scheduling policy, according to its granularity and resource requirements. Stage controllers can monitor event queues and identify unwanted delays. The programmer can split stages or combine them to improve latency or throughput. Event and thread-based systems offer less flexibility. Thread pools can grow and shrink dynamically, but they are typically limited by the host’s resources.
The current popularity of elastic computing and virtualization emphasize the value of shared-nothing models. One alternative for adapting event and thread-based hybrid systems to distributed memory architectures is to replicate the execution environment across multiple hosts and to balance the workload among available processes.
Not only servers but computing-intensive applications can also benefit from hybrid concurrency. The MapReduce model for processing large datasets on shared-nothing environments [7] is an example of aplication pattern that can be implemented over a master/worker infrastructure like MEDA.
Hybrid concurrency models attempt to combine the expressiveness of threads with the flexibility of event-driven systems, exposing, to different degrees, control of the scheduler to the programmer. User-level scheduling seems to be an important mechanism for attaining flexibility and control. However, it remains a difficult facility to implement, usually needing wrappers and transformations that do not always integrate seamlessly.
In 2000, Schmidt and others described a set of hybrid concurrency models in their book on programming patterns [20]. Some of these models and other new ones were proposed over the following ten years. In this paper, we tried to understand the differences and similarities among existing proposals and to identify how they address issues that are important in today’s scenarios.
Pai et al. [18] proposed an classification of concurrency models for the specific case of server applications. They identify four types of servers, some of which can be seen as using the hybrid concurrency model; however, they are not interested in the combination of concurrency models, and their goal is to evaluate the architecture they propose in comparison to these alternative web-server implementations. Li and Zdancewic [14] provide valuable insight into the advantages of combining threads and events and the general structure they present for a hybrid architecture was helpful when building the diagrams that we used to represent each of the hybrid models.
We have proposed a classification of hybrid concurrency that focuses on the abstraction that is offered to programmers and on the resulting application structures. With this approach, we have come to the conclusion that thread based and stage based hybrid models can be seen as similar in structure but different in granularity, flexibility and in their treatment of the control inversion that is typical of events.
Apart from the of inversion of control, the examples we described have different solutions to the problems of resource sharing, thread-pool control, and communication. Dealing with these issues directly in the concurrency infrastructure facilitates elegant implementations of applications because programmers become free to focus on the core logic of the application instead of worrying about synchronizing access to shared memory or delegating tasks to each active thread on the system, but may limit system usability. Besides, some of these issues — for instance, the control of access to shared memory — do not yet have a clear solution even for a specific class of applications.
[1] ADYA, A., HOWELL, J., THEIMER, M., BOLOSKY, W. J., AND DOUCEUR, J. R. Cooperative Task Management Without Manual Stack Management. In Proc. General Track of USENIX Annual Technical Conference (Monterey, CA, USA, 2002), pp. 289–302.
[2] AGHA, G. Actors: a model of concurrent computation in distributed systems. MIT Press, Cambridge, MA, USA, 1986.
[3] ARMSTRONG, J., VIRDING, R., WIKSTRöM, C., AND WILLIAMS, M. Concurrent Programming in ERLANG. Prentice Hall, 1996.
[4] BEHREN, R. V., CONDIT, J., ZHOU, F., NECULA, G. C., AND BREWER, E. Capriccio: Scalable threads for internet services. In Proc. 19th. ACM Symposium on Operating Systems Principles (Bolton Landing, NY USA, 2003), pp. 268–281.
[5] DABEK, F., ZELDOVICH, N., KAASHOEK, F., MAZIèRES, D., AND MORRIS, R. Event-driven programming for robust software. In Proc. 10th. workshop on ACM SIGOPS European workshop (New York, NY, USA, 2002), EW 10, pp. 186–189.
[6] DE MOURA, A. L., AND IERUSALIMSCHY, R. Revisiting coroutines. ACM Transactions on Programming Languages and Systems (TOPLAS) 31, 2 (Feb. 2009).
[7] GHEMAWAT, S., AND DEAN, J. Mapreduce: Simplified data processing on large clusters. In Proc. 6th. Symposium on Operating System Design and Implementation (OSDI’04), San Francisco, CA, USA (2004).
[8] GORDON, M. E. Stage scheduling for CPU-intensive servers. PhD thesis, University of Cambridge, Computer Laboratory, 2010.
[9] HALLER, P., AND ODERSKY, M. Actors that unify threads and events. In Proc. 9th. International Conference on Coordination Models and Languages (Paphos, Cyprus, 2007), pp. 171–190.
[10] HAN, B., LUAN, Z., ZHU, D., REN, Y., CHEN, T., WANG, Y., AND WU, Z. An improved staged event driven architecture for Master-Worker network computing. In Cyber-Enabled Distributed Computing and Knowledge Discovery. CyberC ’09 (Zhangjiajie, China, 2009), pp. 184–190.
[11] HARIZOPOULOS, S. A Case for Staged Database Systems. In Proc. 1st. Conference on Innovative Data Systems Research (Asilomar, CA, USA, 2003).
[12] IEEE/ANSI. Std. 1003.1: Portable operating system interface (posix) – part 1: System application program interface (api). Tech. Rep. Including 1003.1c: Amendment 2: Threads Extension C Language., ANSI/IEEE, 1996.
[13] KILLIAN, C., ANDERSON, J. W., BRAUD, R., JHALA, R., AND VAHDAT, A. Mace : Language Support for Building Distributed Systems. In Proc. ACM SIGPLAN Conference on Programming Language Design and Implementation (San Diego, CA, USA, 2007), pp. 179–188.
[14] LI, P., AND ZDANCEWIC, S. Combining events and threads for scalable network services implementation and evaluation of monadic, application-level concurrency primitives. In Proc. 2007 ACM SIGPLAN conference on Programming language design and implementation (New York, NY, USA, 2007), PLDI ’07, pp. 189–199.
[15] MAZIèRES, D. A toolkit for user-level file systems. In Proc. Usenix Technical Conference (Boston, MA, USA, 2001), pp. 261–274.
[16] ODERSKY, M., SPOON, L., AND VENNERS, B. Programming in Scala. Artima Press, 2008.
[17] OUSTERHOUT, J. Why Threads Are A Bad Idea (for most purposes), Jan. 1996.
[18] PAI, V., DRUSCHEL, P., AND ZWAENEPOEL, W. Flash: An efficient and portable web server. In Proc. USENIX Annual Technical Conference (1999), USENIX Association, pp. 15–15.
[19] PARIAG, D., BRECHT, T., HARJI, A., BUHR, P., SHUKLA, A., AND CHERITON, D. Comparing the performance of web server architectures. ACM SIGOPS Operating Systems Review 41, 3 (2007), 231–243.
[20] SCHMIDT, D., STAL, M., ROHNERT, H., AND BUSCHMANN, F. Pattern-oriented software architecture volume 2: Patterns for concurrent and networked objects. Wiley.
[21] SILVESTRE, B., ROSSETTO, S., RODRIGUEZ, N., AND BRIOT, J. P. Flexibility and coordination in event-based, loosely coupled, distributed systems. Comput. Lang. Syst. Struct. 36, 2 (2010), 142–157.
[22] UPADHYAYA, G., PAI, V. S., AND MIDKIff, S. P. Expressing and exploiting concurrency in networked applications with aspen. In Proc. 12th. ACM SIGPLAN symposium on Principles and practice of parallel programming (New York, NY, USA, 2007), PPoPP ’07, pp. 13–23.
[23] URURAHY, C., RODRIGUEZ, N., AND IERUSALIMSCHY, R. Alua: flexibility for parallel programming. Computer Languages, Systems & Structures 28 (2002), 155–180.
[24] VON BEHREN, R., CONDIT, J., AND BREWER, E. Why events are a bad idea (for high-concurrency servers). In Proc. 9th. Conference on Hot Topics in Operating Systems - Volume 9 (Lihue, HI, USA, 2003), pp. 4–4.
[25] WELSH, M., CULLER, D., AND BREWER, E. Seda: an architecture for well-conditioned, scalable internet services. SIGOPS Oper. Syst. Rev. 35, 5 (2001), 230–243.
[26] YOO, S., LEE, H., KILLIAN, C., AND KULKARNI, M. Incontext: simple parallelism for distributed applications. In Proc. 20th. international symposium on High performance distributed computing (2011), ACM, pp. 97–108.